Ensemble of multiple instance classifiers for image re-ranking
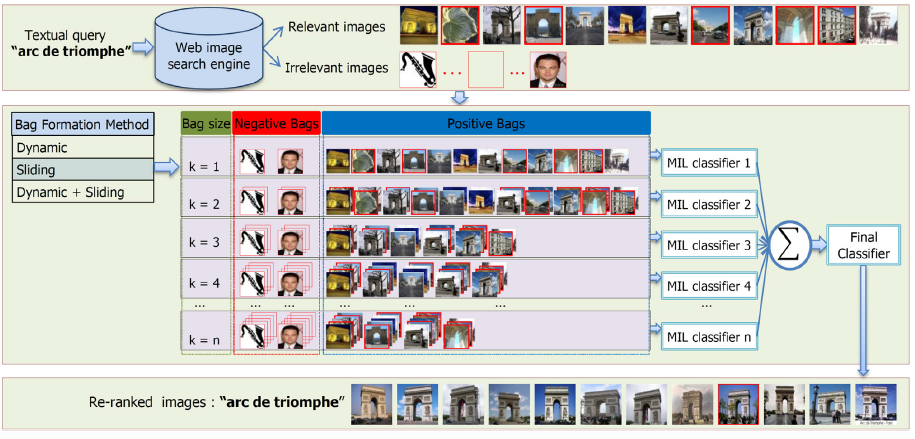 | Text-based image retrieval may perform poorly due to the irrelevant and/or incomplete text surrounding the
images in the web pages. In such situations, visual content of the images can be leveraged to improve the
image ranking performance. In this paper, we look into this problem of image re-ranking and propose a system
that automatically constructs multiple candidate “multi-instance bags (MI-bags)”, which are likely to contain
relevant images. These automatically constructed bags are then utilized by ensembles of Multiple Instance
Learning (MIL) classifiers and the images are re-ranked according to the final classification responses. Our
method is unsupervised in the sense that, the only input to the system is the text query itself, without any
user feedback or annotation. The experimental results demonstrate that constructing multiple instance bags
based on the retrieval order and utilizing ensembles ofMIL classifiers greatly enhance the retrieval performance,
achieving on par or better results compared to the state-of-the-art. [IMAVIS paper (2014)]
|
Action Recognition and Localization by Hierarchical Space-Time Segments
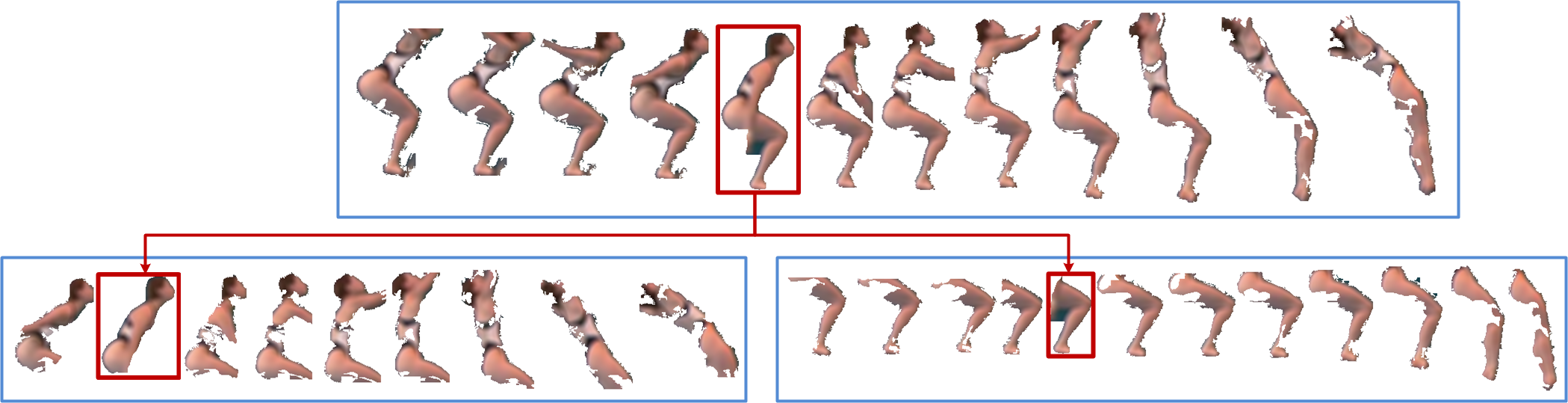 | We propose Hierarchical Space-Time Segments as a new representation for action recognition and localization. This representation has a two level hierarchy. The first level comprises the root space-time segments that may contain a human body. The second level comprises multi-grained spacetime segments that contain parts of the root. We present an unsupervised method to generate this representation from video, which extracts both static and non-static relevant space-time segments, and also preserves their hierarchical and temporal relationships. Using simple linear SVM on the resultant bag of hierarchical space-time segments representation, we attain better than, or comparable to, state-of-art action recognition performance on two challenging benchmark datasets and at the same time produce good action localization results. [project page with code ]
|
On Recognizing Actions in Still Images via Multiple Features
 | We propose a multi-cue based approach for recognizing human actions in still images, where relevant object regions are discovered
and utilized in a weakly supervised manner. Our approach does not require any explicitly trained object detector or part/attribute annotation.
Instead, a multiple instance learning approach is used over sets of object hypotheses in order to represent objects relevant to the actions. We test our method on the extensive Stanford 40 Actions dataset [1] and achieve significant performance gain compared to the state-of-the-art. Our results show that using multiple object hypotheses within multiple
instance learning is effective for human action recognition in still images
and such an object representation is suitable for using in conjunction
with other visual features. [ECCV 2012 Workshop paper]
|
Object, Scene and Actions: Combining Multiple Features for Human Action Recognition
 | In many cases, human actions can be identified not only by the singular observation of the human body in motion, but also properties of the surrounding scene and the related objects. In this paper, we look into this problem and
propose an approach for human action recognition that integrates multiple feature
channels from several entities such as objects, scenes and people. We formulate
the problem in a multiple instance learning (MIL) framework, based on multiple
feature channels. By using a discriminative approach, we join multiple feature
channels embedded to the MIL space. Our experiments over the large YouTube
dataset show that scene and object information can be used to complement person
features for human action recognition.[ECCV 2010 paper]
|
learning actions from the web
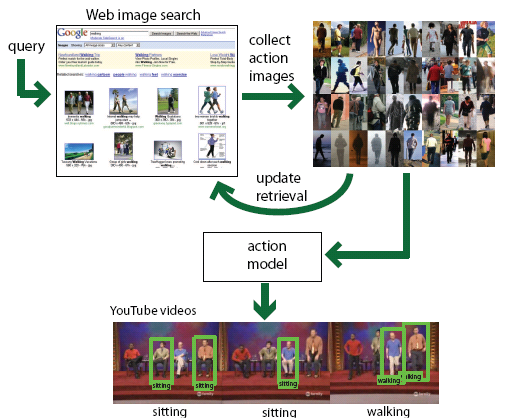 | This paper proposes a generic method for action recognition in uncontrolled videos. The idea is to use imagescollected from the Web to learn representations of actionsand use this knowledge to automatically annotate actionsin videos. Our approach is unsupervised in the sense that itrequires no human intervention other than the text querying. Its benefits are two-fold: 1) we can improve retrieval of actionimages, and 2) we can collect a large generic database of action poses, which can then be used in tagging videos. We present experimental evidence that using action images collected from the Web, annotating actions is possible.[ICCV paper] [dataset]
|
searching for complex composite human activities
 | We describe a method of representing human activities that allows a collection of motions to be queried without examples, using a simple and effective query language. Our approach is based on units of activity at segments of the body, that can be composed across space and across the body to produce complex queries. The presence of search units is inferred automatically by tracking the body, lifting the tracks to 3D and comparing to models trained using motion capture data. We show results for a large range of queries applied to a collection of complex motion and activity. Our models of short time scale limb behaviour are built using labelled motion capture set. We compare with discriminative methods applied to tracker data; our method offers significantly improved performance. We show experimental evidence that our method is robust to view direction and is unaffected by the changes of clothing. [IJCV paper] [CVPR paper] [dataset]
|
histogram of oriented rectangles
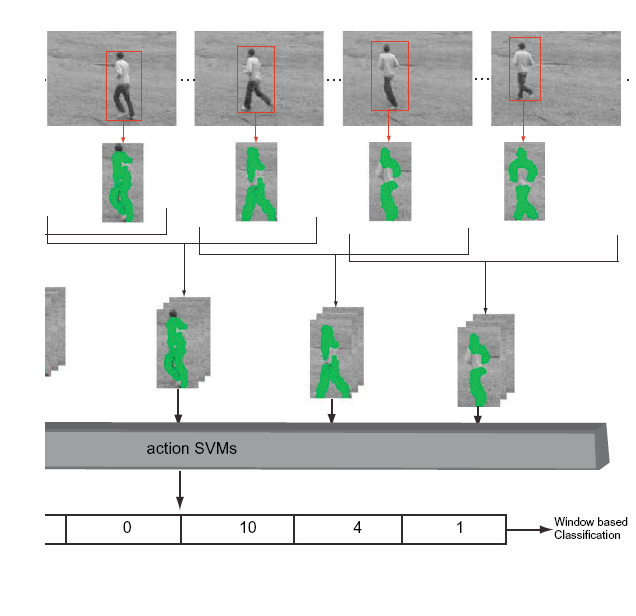 | We propose a novel pose descriptor which we name as Histogram-of-Oriented-Rectangles (HOR) for representing and recognizing human actions in videos. We represent each human pose in an action sequence by oriented rectangular patches extracted over the human silhouette. We then form spatial oriented histograms to represent the distribution of these rectangular patches. We make use of several matching strategies to carry the information from the spatial domain described by the HOR descriptor to temporal domain. [IMAVIS paper] [HumanMotion paper]
|
human action recognition with line and flow histograms
 | We present a compact representation for human actionrecognition in videos using line and optical flow histograms.We introduce a new shape descriptor based on the distributionof lines which are fitted to boundaries of human figures.By using an entropy-based approach, we apply feature selectionto densify our feature representation, thus, minimizingclassification time without degrading accuracy. We alsouse a compact representation of optical flow for motion information.Using line and flow histograms together withglobal velocity information, we show that high-accuracyaction recognition is possible, even in challenging recordingconditions. [ICPR paper]
|
recognizing actions from still images
 | we approach the problem of understandinghuman actions from still images. Our methodinvolves representing the pose with a spatial and orientationalhistogramming of rectangular regions on aparse probability map. Our results over a newdataset collected for this problem show that by using arectangle histogramming approach, we can discriminateactions to a great extent. We also show how we can usethis approach in an unsupervised setting. To our bestknowledge, this is one of the first studies that try torecognize actions within still images.[ICPR paper][dataset]
|
|